Search engine for local markdown files with tagging
This is a local search engine takes advantage of markdown syntax by giving boost to words in headlines, emphasis and other markup. One special feature is that it treats the first line of a markdown file as a list of tags (this behaviour is configurable, the tags line can be prefixed with a term or switched off).
Implemented in Python using Flask, Whoosh and Mistune.
Installation
Clone/fork project. Rename config.py.sample to config.py and adjust the properties. It's only necessary to change the path to your markdown files directory.
# Path to markdown files
MARKDOWN_FILES_DIR = "/home/user/wiki"
The search engine will index all files in this folder and it's subdirectories.
Install the Python requirements. Preferably in a virtualenv, run pip install -r requirements.
Run search engine
Just run python search-app.py and open http://127.0.0.1:5000 in a browser.
Usage
Build/update index
Click on the [Update index] link to re-build the search index. The location of the index can be configured in config.py with INDEX_DIR.
Tags
The first line of a markdown file is treated as a list of tags. How tags are stored can be configured by changing the regex in config.py
# Regular expression to select tags, eg tag has to start with alphanumeric followed by at least two alphanumeric or "-" or "."
TAGS_REGEX = r"\b([A-Za-z0-9][A-Za-z0-9-.]{2,})\b"
Tags can be switched off or can be prefixed (e.g. "tags:"). If prefixed, the line with the tags definitions can be anywhere in the file.
Choose only nouns as tags (recommended)
To enable it, uncomment lines 71-79 in markdown_parser.py and delete line 69
3: # from nltk.tag import pos_tag
68: if tags:
69: return u" ".join([t for t in tags if t not in tags_to_ignore])
70: # Only choose nouns
71: # filtered_tags = []
72: # tagged_tags = pos_tag(tags_line.split())
73: # for t in tags:
74: # if t not in tags_to_ignore:
75: # for word, pos in tagged_tags:
76: # if word == t and pos.startswith('NN'):
77: # filtered_tags.append(t)
78: # break
79: # return u" ".join([t for t in filtered_tags])
This requires to have nltk & numpy installed and to manually download the maxent_treebank_pos_tagger module.
pip install nltk
pip install numpy
Download the module using Python console.
$ python
>>> import nltk
>>> nltk.download()
Show all tags
When going to the starting page or when clicking on [Clear] or the link Seach Directory: ... all tags that are indexed are shown.

Searching
Type in the query as you would in any other search engine. The syntax is defined by the Whoosh library (https://whoosh.readthedocs.io/en/latest/querylang.html). It is possible to search for specific fields, e.g. tags:java headlines:Introduction content:"java 8". If no fields are provided (either in the query or using the checkboxes) the query is applied to all fields. To debug the actual query, it is displayed under the search input field (this can also be switched off).
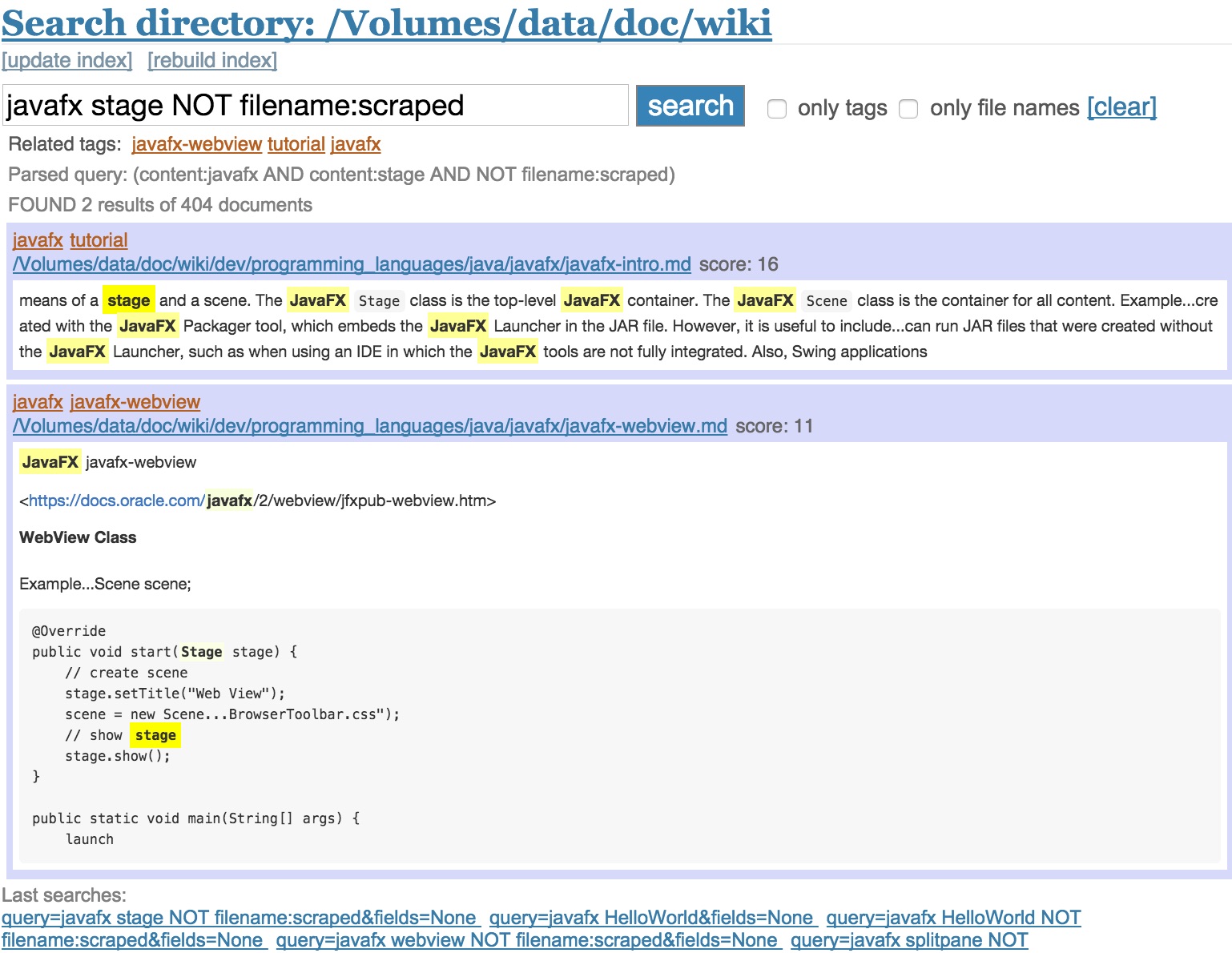
Searching for tags only
Every search result displays the tags of a file and related tags to the query. Clicking on one tag searches for this tag only. Alternatively, check the only tags checkbox.
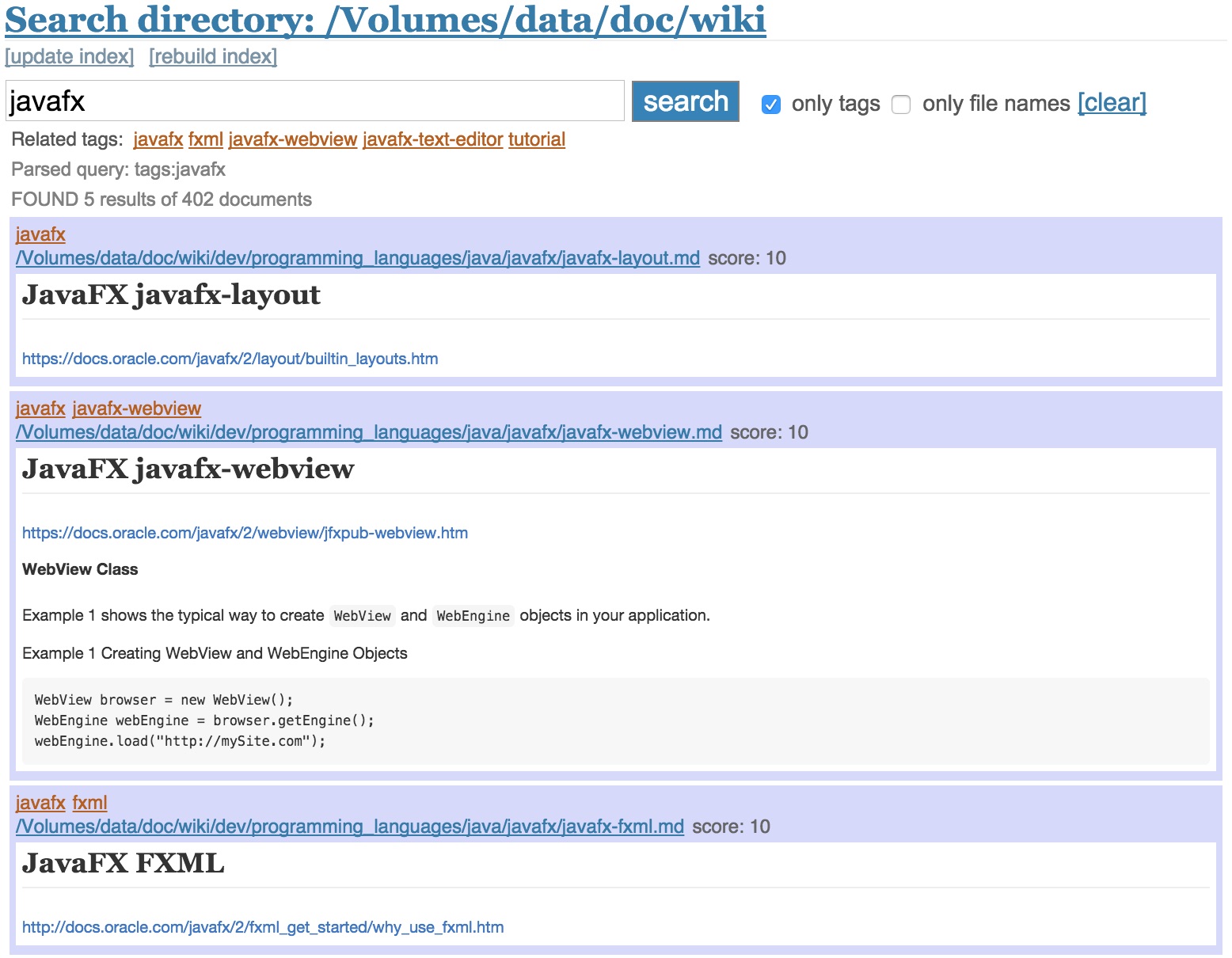
Searching for file path only
If checking only file names the search query is limited to the file paths. The "cleared" search page (clicking on [clear] or the search directory link) shows additionally a list of all subdirectories. Clicking on one of those directories limits the search to files that match their path with the directory name. This list of directories gets updated when doing an index update and is stored in a plain text file named directories.txt.
Open a file in your local editor
Under the tags of a search result is the path of that file. By clicking on the link it can be opened in your default editor. The command to run the path with is defined in the configuration with EDIT_COMMAND. This has been tested on MacOS (Windows probably requires to specify the full path to an executable). With the default setting, if clicking on the path the following command is executed: edit <PATH>
Last searches
On the bottom of the search result page is a list of the last searches. They are stored in a plain text file named last_searches.txt
Schema
The search schema is defined in search.py. Adjust it if you want to give a different boost to fields.
class Search:
def open_index(self, index_folder, create_new=False):
schema = Schema(
path=ID(stored=True, unique=True)
, filename=TEXT(stored=True, field_boost=100.0)
, tags=KEYWORD(stored=True, scorable=True, field_boost=80.0)
, headlines=KEYWORD(stored=True, field_boost=60.0)
, doubleemphasiswords=KEYWORD(stored=True, field_boost=40.0)
, emphasiswords=KEYWORD(stored=True, field_boost=20.0)
, content=TEXT(stored=True)
)
Tip: changing between directories without rebuilding the index
If you have different markdown files that you don't want to belong to the same index, it is quite easy to switch between different locations without the need to rebuild the index each time. Arrange your config.py the following way:
FOLDER = "write"
ROOT = "/Volumes/data/doc"
MARKDOWN_FILES_DIR = ROOT + "/" + FOLDER
INDEX_DIR = "/Users/bwenzel/appdata/mdsearch/" + FOLDER
Now when changing the FOLDER parameter the search is using a different index (requires restart). You could even read this parameter from the environment (e.g os.environ.get("FOLDER")) or providing the folder using using a bash script (e.g. search.sh):
#!/usr/bin/env bash
export FOLDER="$1"
cd /Users/bwenzel/dev/projects/markdown-search
source venv/bin/activate
python search-app.py
Now you point the search engine to your local folder by running: search.sh write.
If you want to learn more about the project, have a look at the related post: http://www.bernhardwenzel.com/blog/2015/08/17/how-to-have-an-elephant-brain/